I’ve wondered Why Rails becomes slow with JIT for a long time. Today, I’m pleased to share my answer to the question in this article, which I spent three years of my life to figure out.

"MJIT Does Not Improve Rails Performance"
As I wrote in Ruby 3.0.0 Release Note and my previous post, we thought:
it is still not ready for optimizing workloads like Rails, which often spend time on so many methods and therefore suffer from i-cache misses exacerbated by JIT.
We thought Ruby 3’s JIT a.k.a. MJIT Does Not Improve Rails Performance and Rails Ruby Bench gets slower, not faster. That’s what I observed last year too.
Because of that and to support environments without compilers, Matz is thinking about introducing JIT that does not invoke compilers, MIR or YJIT.
Why does Rails become slower on Ruby 3’s JIT?
People have thought:
- They were very focused on this one synthetic benchmark called Optcarrot.
- GCC is not really equipped to optimize dynamically typed code.
- There are a lot of useful optimizations that got lost in the shuffle, and a lot of code that hasn’t yet been rewritten to use it.
I mean, I've literally thought about optimizing Rails by MJIT for over 3 years, and I've introduced several optimizations designed for such workloads. We do rely on GCC to ease our maintenance, but the reason why it optimizes some benchmarks is that it implements various Ruby VM-level optimizations that don’t really depend on GCC, not just that it uses GCC. Most of RTL-MJIT’s optimizations were already ported to or experimented with YARV-MJIT after we shuffled the code to make it work with YARV, and it’s now faster than RTL-MJIT because of that and many other improvements after it.
Then… why?
Is it because we use C compilers?
MJIT writes C code and invokes a C compiler to generate native code. Slow compilation time aside, which doesn't impact the peak performance, I see two performance problems in using C compilers as a JIT backend.
First, using a C compiler for code generation makes it hard to implement some low-level techniques, such as calculating a VM program counter from a native instruction pointer, retrieving VM stack values from a native stack, patching machine code, etc. One such optimization that YJIT implements and MJIT doesn’t is dispatching JIT-ed code from direct threading just like normal VM instructions. I ported the technique to MJIT and even tested generating a whole method with an inline assembler, but it didn’t seem to help the situation and MJIT’s dispatch wasn’t really slower than that.
Second, there’s an overhead caused by using dlopen as a loader. Whenever you call dlopen, it creates multiple memory pages for different ELF sections. More importantly, methods generated by different dlopen calls are on different pages. However, we removed the latter problem by periodically recompiling all methods to a single binary, which I call "JIT compaction". Also, function calls from a shared object are a bit slow. In fact, Ruby becomes a little slower if you compile Ruby with --enable-shared. The same overhead applies to MJIT. Though it’s usually just a couple of cycles after the first call is made and dynamic resolution is finished. I also tested loading .o files using shinh/objfcn, but compiling all methods in a single file and using dlopen weren’t slower than loading .o files.
i-cache misses by compiling many methods?
I’ve measured JIT-ed code with Linux perf so many times. I even wrote a perf plugin for it. Through the investigation, I observed cycles stalled for filling i-cache. Because the number of i-cache misses generally increases when you compile more methods, we changed the default of --jit-max-cache from 1000 to 100 in Ruby 2.7 to address the problem. And it indeed helped Rails performance. So I’ve believed JIT-ing a lot of methods is a bad thing.
However, Shopify’s YJIT, which compiles every method called more than once, achieved the same performance as the interpreter after compiling 4000 methods. Which, doesn’t really make sense if you assume the more methods you JIT, the slower the code runs.
What if we just compile all methods like YJIT? I tested it in older versions and it didn’t go well, which is why I haven’t tried it again until very recently. But in Ruby 3.0, I implemented an optimization that eliminates most of the code duplication across different methods and significantly reduces code size. With that, could MJIT-generated code perform well just like YJIT?
The “compile all” magic
Yes, that’s what we needed. If you compile all benchmarked methods instead of just the top 100 methods, the JIT makes Rails faster.
See this gist for benchmark details. Note that some benchmarks are forked by me for reasons explained later. Following results are measured under a single-threaded condition and run at a Rack level.
Sinatra Benchmark
This benchmark was from an article saying "enabling the JIT makes Sinatra 11% slower!", which just returns a static string from Sinatra.
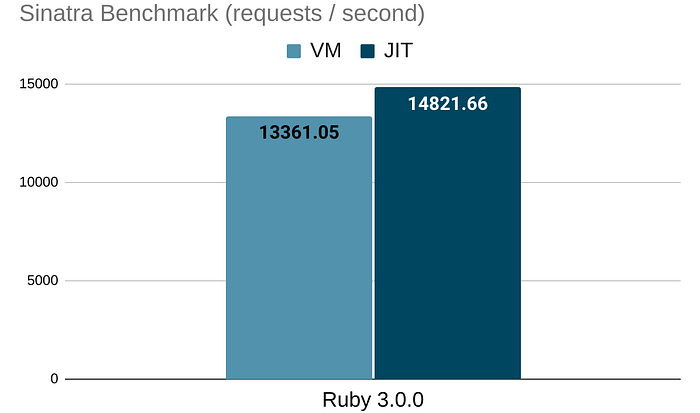
Guess what? JIT makes it 11% faster instead of slower now.
Rails Simpler Bench
Rails Simpler Bench was authored by Noah Gibbs. The default benchmark endpoint returns a static text. So it's a Rails version of the above benchmark.
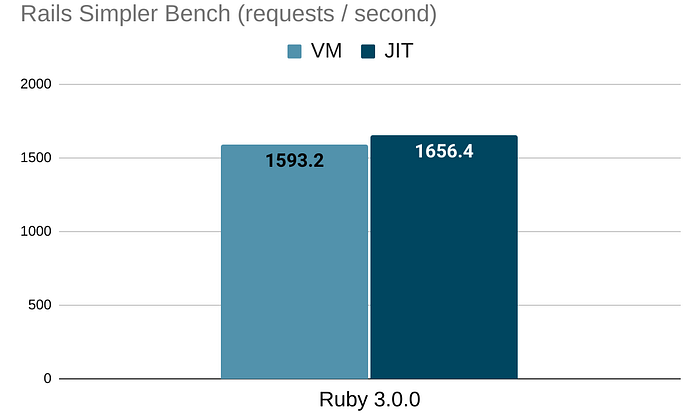
JIT makes it 1.04x faster. The difference is not as significant as Sinatra, but this is the first time we see the JIT makes Rails faster, not slower.
Railsbench
Railsbench measures the performance of HTML #show action of a controller generated by "rails g scaffold". It was originally headius/pgrailsbench used by the JRuby team, I forked it as k0kubun/railsbench to upgrade Rails, and Shopify/yjit-bench uses that too.
Despite its simplicity and benchmark convenience, it captures many real-world Rails characteristics. It uses ActiveRecord, for instance.
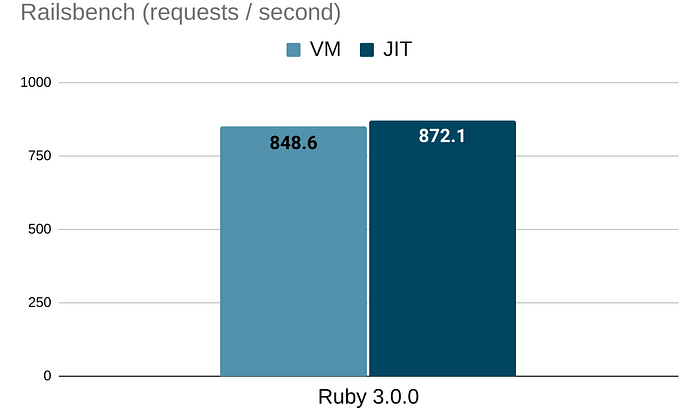
It's 1.03x faster. Not significant, but it's way better than a slowdown, right?
Discourse
Discourse is one of the most popular open-source Rails applications in the world. You can see it at Twitter Developers, GitHub Support, CircleCI Discuss, and more.
So it's pretty clear that Discourse is a real-world Ruby workload. The important thing in this context is that it has its own benchmark harness. Noah Gibbs's Rails Ruby Bench is based on Discourse too.
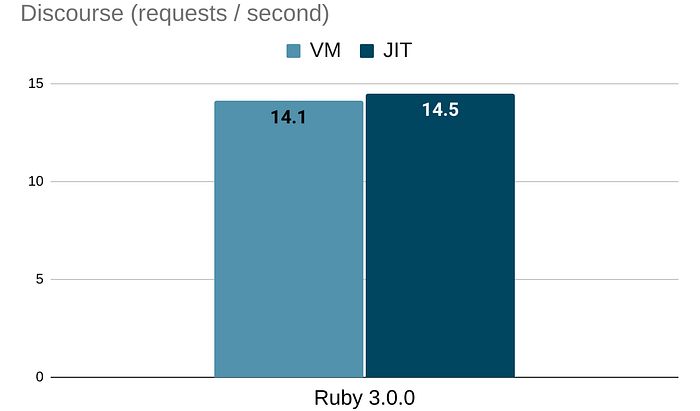
JIT can make Discourse 1.03x faster! One complication here, however, is that Discourse enables TracePoint and all JIT-ed code is canceled when TracePoint is enabled. Because Zeitwerk uses TracePoint, I needed to switch its autoloader back to the classic autoloader. So it's not ready to use the JIT for Discourse yet. But this proves the JIT is useful for real-world application logic.
Why does compiling everything make it faster?
To spot locations impacting metrics like i-cache misses, I've tried tools like perf and cachegrind before, but because the slowness appears everywhere and no single place shows a significant difference, it's hard to tell the exact reason.
Let's take a look at how the number of compiled methods impacts the performance with Railsbench.
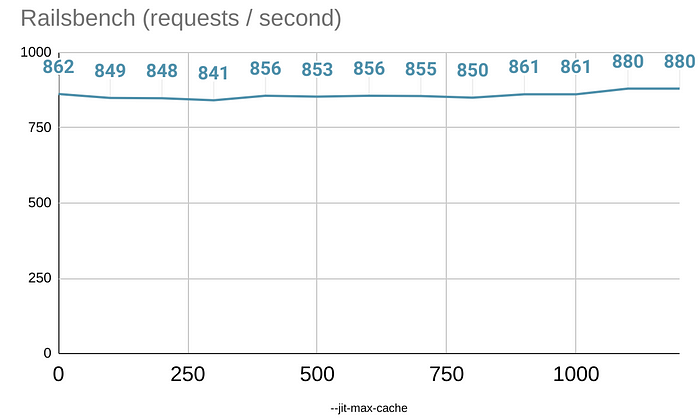
The number of benchmarked methods was roughly 1200. When you have only VM interpretation, it's faster than most of the VM/JIT-mixed execution. But once you compile everything and use JIT-ed code most of the time, it actually becomes faster than the baseline.
What Maxime, the author of YJIT, thought was that thrashing between VM and JIT is the biggest issue because they could evict each other from i-cache and less-predictable VM dispatch makes it harder to prefetch code. She also proved in her 30k_methods benchmark that large code can run faster as long as you stay in linear predictable JIT-ed code. MJIT would share many of these characteristics too even while its code may not be as linear as YJIT's.
I think our significant code size reduction in Ruby 3.0 contributed to making this possible as well.
So, should I use JIT on Rails?
We're almost there, but we have some stuff to be fixed before bringing this to production.
Ruby 3.0.1 bug that's not in 3.0.0
One of the backports to Ruby 3.0.1 causes JIT compilation failures. 3.0.1 is significantly slower than 3.0.0 if you use JIT. Let's wait for the next release.
Ruby 3 bug that stops compilation in the middle
There's a bug that the JIT worker stops compiling the remaining methods in edge cases. You cannot reproduce the above speed if it happens. Please wait until this fix is backported and released.
Incompatibility with Zeitwerk / TracePoint
In ruby 2.5, Koichi, the author of TracePoint, implemented an optimization that makes overall Ruby execution faster as long as you never use TracePoint. I've thought you should not enable TracePoint if you care about performance. Thus MJIT has not supported TracePoint.
However, Byroot has found that it doesn't have a significant impact on VM performance nowadays. So the problem is only associated with JIT. Given that Zeitwerk disables TracePoint after eager loading finishes, now I'm thinking about re-enabling all JIT-ed code when all TracePoints get disabled.
Incompatibility with GC.compact
We either need to compromise performance by making every memory access indirect or recompile many methods whenever GC.compact is called. It has not been implemented, so all JIT-ed code is canceled for now.
The default value of --jit-max-cache
To compile everything, the default 100 of --jit-max-cache was too small. I'll change it to maybe 10000 in Ruby 3.1, but you'd need to override the default for Ruby 3.0.
Scalability of "JIT compaction"
If you want to reproduce the above benchmark results, you have to see the "JIT compaction" log at the end of --jit-verbose=1 logs. However, because the compacted binary has all methods and we currently have no way to distinguish which version of JIT-ed code is in use, the compacted code is almost always not GC-ed properly. Because of that, we restricted the max number of "JIT compaction" to 10% of --jit-max-cache (10 times by default). If JIT continues to compile methods after the last JIT compaction, it'll be slow.
Also, it takes a lot of time before "JIT compaction" is triggered. See this benchmark result for how long MJIT takes to reach the peak performance. If you measure MJIT's performance while GCC is running or before "JIT compaction", it would be often slower than the baseline.
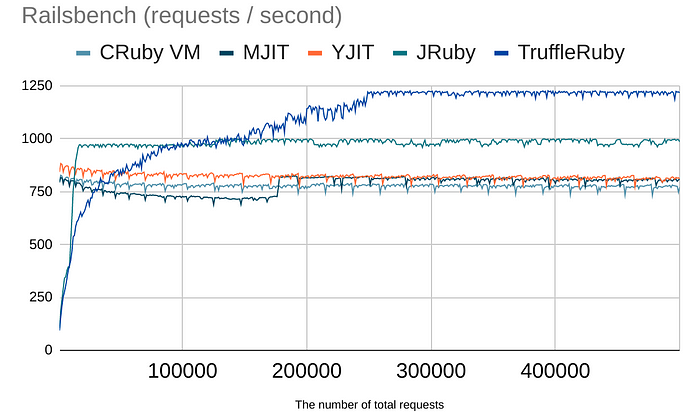
I hope using MIR instead of GCC will shorten the warmup time in the future.
Next steps
I don't care which JIT backend we use to generate machine code out of MJIT, MIR, or YJIT. What I do care about the most is the performance in real-world workloads and optimization ideas implemented in the JIT compiler on top of the backend, which will continue to be useful even if you replace MJIT with MIR and/or YJIT.
In addition to approaching the problems discussed above, I'm thinking about working on the following things, which were slightly changed from the previous article.
Ruby-based JIT compiler
I considered "Ractor-based JIT worker" in the previous article because process invocation is something Ruby is good at and I thought doing that at a Ruby level might make it easier to maintain locks, in addition to using Ruby to easily maintain complicated optimization logic.
However, I found that running multiple Ractors has its own overhead unlike running only the default Ractor. So now I'm thinking to continue to maintain the JIT worker in C, but starting and stopping a Ractor whenever the JIT compilation happens so that we won't see the multi-Ractor overhead once it reaches the peak performance. We'd need to check if the overhead is insignificant compared to GCC's compilation time first though.
Faster deoptimization
One theme in the previous article was "On-Stack Replacement", but I split it to "Faster deoptimization" and the next "Lazy stack frame push" this time. Ultimately, On-Stack Replacement is just one way to implement those optimizations, and whether we use OSR or not doesn't really matter.
One of the reasons why we don't support TracePoint and GC.compact was to avoid adding too many branches in the code for deoptimization. If there's no extra overhead for doing it, it'll be easier to introduce the support.
Lazy stack frame push
From Ruby 3.0, we started to annotate methods that don't need any stack frame to be pushed. The number of methods we can annotate as such is limited for now because object allocation might raise NoMemoryError and a backtrace needs the frame. If we can lazily push the frame when it's being raised, we can skip pushing the frame. It's tricky to implement that with MJIT, but it'd be useful for reducing the method call overheads.
Sponsors
My contribution to OSS like the JIT, ERB, Haml, and IRB and my own projects like Hamlit, sqldef, pp, mitamae, and rspec-openapi has been supported by the following GitHub Sponsors. Thank you!

